Serious MT technology development requires ongoing efforts and research to continually improve the performance of systems and to address important emerging requirements as the use of MT expands. Researchers have been working on MT for over 70 years and success requires a sustained and continuing effort.
These efforts approach the goal of producing as close as possible to human-quality MT output in multiple ways, and these improvement strategies can be summarized in the following ways:
- Acquire better and higher volumes of relevant training data. Any AI initiative is highly dependent on the quality and volume of the training data that is used to teach the machine to properly perform the task.
- Evaluate new algorithms that may be more effective in extracting improved performance from available training data. We have seen the data-driven MT technology evolve from Statistical MT (SMT) to various forms of Neural MT (NMT) using different forms of deep learning. The Transformer algorithm which also powers LLMs like GPT-4 is the state-of-the-art in NMT today.
- Use more powerful computing resources to dig deeper into the data to extract more learning. As the demand for translation grows with the massive increases in content and ever-expanding volumes of user-created content (UGC) it becomes increasingly important for MT to handle massive scale. Today there are global enterprises that are translating billions of words a month into a growing portfolio of languages and thus scalability and scale are now key requirements for enterprise MT solutions. Some researchers use more computing during the training phase of the MT model development process as there can be quality advantages gained at inference from doing this extra-intensive training.
- Build more responsive and integrated human-machine collaboration processes to ensure that expert human feedback is rapidly incorporated into the core data used to tune and improve these MT engines. While the benefits gained from more and better data, improved algorithms, and more computing resources are useful, the integration of expert human feedback into the MT model's continuous learning is a distinctive advantage that allows an MT model to significantly outperform models where only data, algorithms, and compute are used.
- Add special features that address the unique needs of large groups of users, or use cases that are being deployed. As the use of MT continues to build momentum with the enterprise many specialized requirements also emerge e.g. enforcement of specific terminology for brand integrity, profanity filters to avoid egregious MT errors, and improvement of document-specific content awareness.
All these different approaches have the goal of producing improved MT output quality and it will require progress along all of these different fronts to achieve the best results.
The ModernMT development team pursues ongoing improvements along all these fronts on an ongoing basis, and ModernMT V7 is the result of several measured improvements on many of these dimensions to provide improved performance.
As machine translation (MT) continues to evolve and expand beyond the traditional use case areas such as e-commerce, global collaboration, and customer care, those interested in the expanding future of localization are now also looking to use generative artificial intelligence (AI) and, in particular, large language models (LLMs) such as OpenAI’s GPT

Unlike typical Neural MT, LLMs prioritize fluency over accuracy. But while LLMs show promising results in improving the fluency of translations, they can also produce confabulations (hallucinations), i.e. output that is inaccurate or unrelated to the input data and thus require careful monitoring and oversight to ensure accuracy.
With the latest release of ModernMT (V7), Translated has introduced a novel technique to increase the accuracy of neural MT models, called “Trust Attention,” which can also be used to address reliability within generative AI models.
The design and implementation of Trust Attention was inspired by how the human brain prioritizes trusted sources in the learning process, linking the origin of data to its impact on translation quality.

ModernMT V7 preferentially uses the most trusted data (identified by users) and thus the highest quality and most valuable training data has the greatest influence on how a model performs. This is in stark contrast to most MT models which have no discernment of data quality and thus tend to perform using only statistical density as the primary driver of model performance.
The Trust Attention capability prioritizes its learning based on data value and importance like how humans sift through multiple sources of information to identify the most trustworthy and reliable ones. Data extracted from translations performed and reviewed by professional translators is always preferred over other data, especially unverified translation memory content acquired from web crawling, which is typically used by most MT systems today.
The development team at ModernMT considers Trust Attention to be as significant an innovation as Dynamic Adaptive MT engines. It is the kind of feature that can dramatically improve MT system performance for different use cases when properly used.
According to an evaluation by professional translators, done to validate the beneficial impact, Trust Attention alone improves MT quality by up to 42%, and by an average of 16.5% in cases across the top 50 languages. Interestingly, even many high-resource languages, such as Italian and Spanish, showed significant improvements (in the 30% range) in human evaluations.

ModernMT V7 New Features: Up to 60% Better MT Quality
ModernMT V7 is the evolution of Translated’s renowned adaptive MT system, recognized as a leader in the Machine Translation Software Vendor Assessment for enterprises by IDC Marketscape 2022, and as “the most advanced implementation of responsive MT for enterprise use” in CSA Research’s 2023 Vendor Briefing.
In addition to Trust Attention, ModernMT V7 includes several other new features that further enhance the reliability and dependability of MT output. Here are the most impactful:
- Advanced Terminology Control: Along with its ability to learn the client’s terminology from past translations, ModernMT now provides companies with self-managed glossary control to ensure brand and context-specific terminology consistency. This ability to enforce terminology has not been needed in the past because the dynamic adaptive MT technology acquires terminology very effectively even without this feature.
- DataClean AI: V7 relies on a new sanitization algorithm that identifies and removes poor-quality data to refine the training material and reduce the likelihood of hallucinations. The close examination of errors over many years has provided clues on the root causes of strange output from MT engines. This learning and related benefits also transfer to LLM-based MT engines should they become more viable in the future.
- Expanded Context: ModernMT can now leverage up to 100,000 words of document content —Four times more than GPT-4 - to preserve style and terminology preferences, providing unparalleled document-specific accuracy in MT suggestions and providing controls to solve persistent problems such as gender bias and inconsistent terminology.
- Profanity Filter: V7 masks words in translation suggestions that could be regarded as inappropriate in the target language, minimizing the possibility of cultural offenses.
The combined effect of all the improvements and innovations described above has a significant impact on the overall performance and capabilities of ModernMT.
The MT quality is now considered to be 45% to 60% better than the previous version according to systematic human evaluations.
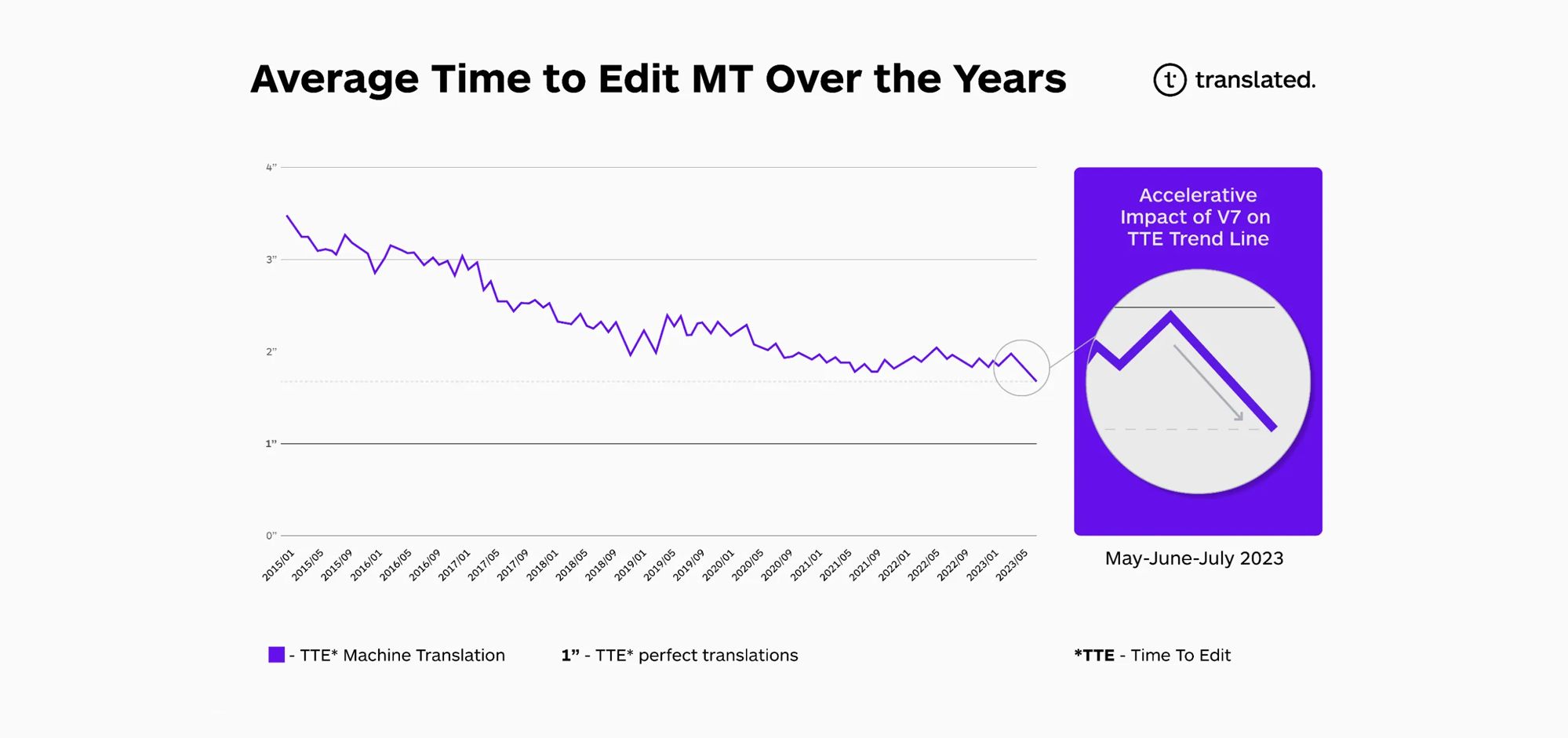
These improvements have greatly reduced the Time to Edit (TTE) for MT suggestions. At the end of July, the aggregate TTE measured across tens of thousands of samples showed a 20% reduction, reaching a record low of 1.74 seconds. This milestone indicates an acceleration towards singularity in translation, a trend further supported by preliminary TTE data collected continuously since the 1.74 seconds record was established.
The Hallmark of the Symbiosis Between Translators and MT
ModernMT V7 is available in 200 languages and covers all the fastest-growing economies likely to emerge over the next 20 years. Its hallmark is the ability of the MT model to learn from corrections in real time, enabling a powerful collaboration between the expertise of professional translators and the speed and capacity of MT.
Thanks to this unique approach, combined with Translated’s vast community of professional translators and leading AI-enabled localization solutions (Gartner 2022), Airbnb was able to ditch the translate button and simply make multilingual content pervasive and comprehensive across the platform and become one of the top 3 global brands (Global by Design 2023).
Success stories like that of Airbnb and others, along with market research that shows the ever-growing demand for more multilingual content, have led Translated to estimate that once MT reaches what is commonly referred to as “parity with human translation” (singularity in translation), we can expect a 100-fold increase in MT requests alongside a 10-fold growth in demand for professional translations.
We are entering a new era in which significantly larger volumes of content will be translated automatically. In this scenario, professional translators play an increasingly important role, not only in guiding the MT through the adaptive process but also in ensuring that the key messages are appropriately conveyed. By engaging the best translators with the best adaptive MT, companies can now take on projects that simply weren’t feasible before.
Moving Towards LLMs for Translation
Recently, Translated conducted a large-scale study to compare the performance of the most advanced MT systems with LLMs in terms of enterprise readiness. The findings showed real potential for LLMs, particularly in terms of more fluent translation quality, and also revealed areas where improvements are needed. Based on this research, Translated believes elements of both MT systems and LLMs will be critical as we move forward, and plans to provide in-depth insights into using LLMs in translation in the coming weeks and months.
Comments by John Tinsley of Translated SRL on LLM-based Translation in November 2023:
❗ LLMs - the new default for machine translation ❗
I've seen a lot of commentary along these lines over the past few months. I've also seen a lot of well-articulated commentary, not strictly opposing this line, but with added nuance and context (a challenge on the internet!)
I wanted to offer my two cents, from being at the forefront of these developments through actually building the software, and from having many conversations with clients.
In summary, today, LLMs are not fit for purpose as a drop-in replacement for MT for enterprises.
More broadly, any general-purpose GPT application will find it super challenging to outperform a purpose-built enterprise solution that considers an entire workflow in a holistic way (note, the purpose-built solution could be GPT-based itself, but with a much narrower scope).
🧠 As a concrete example, at Translated, we've built a version of ModernMT that uses GPT-4 as a drop-in replacement for our Transformer model (while retaining the framework in ModernMT that allows us to do real-time adaptation). We've also built, and continue to test, a version of ModernMT with other open source LLMs fine-tuned for translation.
While we find that they perform well in terms of quality on some content types and some languages, it's far from unanimous across the board. And that's just quality. Other critical enterprise factors such as speed, cost, and importantly, information security, are just not there yet. Similarly, language coverage for LLMs is a challenge as there are large discrepancies in performance, particularly for content generation.
I appreciate there's a lot of downward pressure today to use AI across workflows, particularly in localization teams for translation and content creation. Let me hop on my soapbox to give you some information that might help with those conversations...
📣 If you're using MT, you're already using very advanced AI! 📣
You probably already know that the T in GPT stands for Transformer. But did you know that the Transformer was invented at Google in 2017...specifically for machine translation!? So what we're seeing today is a repurposing of that technology for a different application (generative AI) other than translation.
There will come a day, possibly soon, when it's better across the board to use LLMs for translation. When that happens, it will become the standard and people will stop talking about it. Just like when Neural MT came on the scene ~6 years ago.
When it happens, Translated will have already deployed it in ModernMT and worked out the best way for you to adapt it to your business. We already have a lot of ideas. We already have a lot of data from the testing I mentioned earlier. And in the meantime, we still have what I believe to be the most complete enterprise translation solution available.













